
2024 Recap of my SWE Career

Kenneth Wong
2025-01-06
10 min read
A brief summary of what I have learnt in 2024 as a software engineer.
life
I plan to recap my journey as a software engineer this year as a lot has happened. I want to reflect on the highlights, lowlights and learnings to further grow as a software engineer.
1. Moved to San Jose
I moved from NYC to San Jose earlier this year due to a reorg. My team was split between San Jose, NYC and China, I was a little sad that I had to work remotely with my Tech Lead due to the 3 hour time difference. The silver lining was that I didn't have to do (very) late night communications with my China counterparts.
Moving here has definitely helped me focus as there is not much to do here (and I don't have a car). I have been a lot more productive and am motivated by the grind culture here in the Bay Area. Moreover, I feel more engaged with the SWE community as I'm living in the heart of the action; seeing the HQ of big tech companies and all the engineers wearing their merch.
2. Reading software engineering books
Wanting to accelerate my career, I have been reading software books. I did a lot of research and soul-seraching to find the best books to read. The software related books that I have read were:
Designing Data-Intensive Applications: This book is a must-read for any software engineer. It covers the fundamentals of distributed systems and how to design data-intensive applications.
Building Microservices: Working primarily with microservices and having read DDIA, I thought a great transition from theoretical to practical would be to read this book.
Fundamentals of Data Engineering: Learning that a Backend Engineer's scope is more than just API design and actual bleeds into the Data layer, I decided that I wanted to learn more about Data Engineering. I will expand more in the later section
Building a Career in Software: Great book to learn about growing your career as a software engineer. Not a technical book, but rather an emphasis on soft skills, office dynamics and how to grow within a company.
System Design Interview - An insider's guide: Great book to have a high level overview of key components of a highly scalable, distributed system to tackle system design. I often used wikipedia and chatGPT to deep dive on several of the topics.
The Phoneix Project: Breaks-down how the software department/ methodologies are built within a company to tackle specific problems through a narration of a fictitious company.
3. Worked on high impact projects
I got to work on a few high impactful projects.
SDUI Promotion Cards: I worked alongside my TL to design and implement server-driven promotion cards in Tiktok Studio to promote the newly launched Tiktok Studio app. This project was exposed to over 20M+ users and have successfully directed over 1M+ Tiktok Users, supersceding our OKR by over 150%.
Resource Management Platform: I lead a team of 8 engineers to architect and develop an MVP Resource Management Platform. Despite the tight deadline, we managed to deliver the MVP on time and have since iterated on the platform to support more use cases.
4. Lessons learnt
4.1 Data is Everything
After reading Fundamentals of Data Engineering and having worked on several large scale data projects, I realised how important data is for projects and businesses.
I learnt a lot about business data managements and how data should be managed to reduce cloud costs. From the shift from ETL to ELT due to improvement of compute in Data warehouses to separation of storage and compute, I got a glimpse of what is commonly handled by the Data Engineering team.
The most important reason for massive data stores like data warehouses and data lakes is to store as much raw data as possible, store first, then worry about transformation and figuring out the correct strategy to transform the data. And it is because of this that data temperature exists and budget data storage solutions like AWS glacier exists.
One think I want to deep dive on is Data Streaming and grasp the fundamentals of Distributed Joins (Broadcast Joins or Shuffle Joins). I have seen my team members work with Flink for realtime event processing and I hope that I get to work on this in on future projects as it is critical for building real-time personalized features (in-app notifications, fraud detection...).
4.2 Be persistent and creative debugging
I have learnt a lot seeing my God-like 10x engineer TL debug issues. From that, I have learnt to be persistent and creative in debugging issues:
Don't just stick to the server-side code base, also comb through the client-side codebase to understand the entire end-to-end process of the API lifecycle.
Don't just look at the networking tool when trying to debug web APIs, look into the developer console as well.
Check run logs of each service instance to figure out the issue and what went wrong. Logs are extremely important in debugging.
4.3 Business-metrics are everything
When it comes to high impact projects and getting that sweet quarterly bonus, business-metrics are everything. Depending on how your team/company functions, this may be a factor of luck (EM handing you the PRD), if company culture engineering driven (not common in TikTok), then your impact is in your own hands.

In Q3 of 2023, I got an award for outstanding achievements for my efforts of redirecting 1M+ users to the Tiktok Studio app, and for growing the in-app Tiktok Studio DAU by 300%. These projects were not insanely challenging nor involving lots of XFN collaboration and coordination, I got the award simply due to the nature of the project I worked on, high visibility and high impact.
Moving forward, if my goal were to grow within a company, I would focus on projects that have a direct impact on the business metrics. However, if my goal were to be a better engineer, I would tackle challenging projects that would help me grow as an engineer.
4.4 Choice of data storage matters
Reading about differences in data storage is one thing, but practically working with them is another. We've all read about the classic SQL vs NoSQL debate, but I have learnt that the term NoSQL is actually an umbrella term for a huge variety of databases with different quirks.
I also wonder why I didn't have to use a cache when dealing with 25K+ R/W QPS, it almost seemed like an anti-pattern. But then, combing through the docs, I noticed that that datastores like redis or cassandra can support up to 1 Million R/W QPS. This is obviously impossible for a single instance of MySQL. This prompted me to look under the hood of these datastores and how they differed and what made the difference so drastic. That is when I learnt about LSM trees, Memtables, WAL, SSTables, B-Trees... and how they all play a part in the performance of the database.
On top of that, learning about CAP theorem, DB ACID compliances, I learn to better choose the right data store based on my project requirements. If I wanted eventual consistency, high RW QPS then I would probably opt for a NoSQL database like Cassandra. If I wanted strong consistency, ACID compliance and transactions, then I would opt for a SQL database like MySQL.
4.5 Strong-coupling
When designing systems, I also consider the coupling of systems. Generally, the consensus seems to be that a strong coupling of systems are bad as it could introduce co-dependence, potentially breaking changes and rigidity.
This led me to deep-dive into event-driven architectures using Message Queues to decouple systems. However, this doesn't immediately solve the issue of coupling as the issue of message loss, message duplication, message ordering, message delivery guarantees... all come into play. Therefore, I read about idempotenece, at-least-once delivery, at-most-once delivery, exactly-once delivery... and how they all play a part in ensuring that the message is delivered correctly.
4.6 Difference between Mobile and Desktop users
When designing a system and API endpoints, we also have to consider the origin of the call, whether it is from a user's mobile device or laptop, and whether it is connected to wifi or cellular network. This is important as we have to take into account connection strength, payload size to provide a good UI/UX experience for the user. E.g, It wouldn't make sense to make pagination of size 25 on both devices if the screen sizes differ so much, a much better solution would be to do chunking/ lazy-loading or infinite scrolling for mobile devices.
4.7 Parallel programming, concurrency and asynchronous programming
All these terms always show up when talking about Go. So I read through how Go handles parallel programming and what is happening under the hood. I learnt about the Go's non-preemptive M:N go routine scheduler, concepts of the like of kernel threads, blocking system calls etc...
With asynchronous programming, knowing what happens under the hood is important to writing high performant code. We need to know whether an operation is CPU bound or IO bound. If it is IO bound, then we can leverage on asynchronous programming to run other tasks while waiting for the IO operation to complete. If it is CPU bound, then we can leverage on parallel programming to run the task concurrently. Simply setting a task as async when it is CPU bound is a big mistake as it does nothing to help with performance, especially for single-threaded web server frameworks like Node.JS.
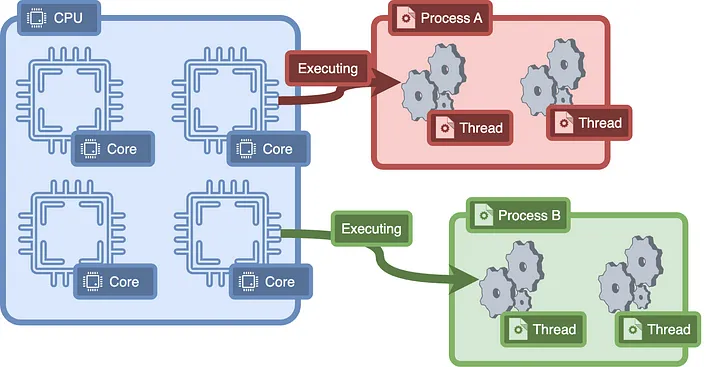
A gross generalization Go handles this by having a process in each CPU core, and each CPU core have multiple threads. Whenever a thread blocks, it looks into it's thread pool to see if there are any other threads that can be run. If not, it will look at the global thread pool, and if not it can steal threads from other CPUs.
4.8 Most optimal solution is not always the right solution
Knowing that the most optimal solution is not always the right solution is important. I have seen many overkill designs for small projects with low ROI that simply can't be justified. When writing out our technical solutions, it is important to think about the ROI, timeline and resource constraints before deciding on the best solution.
Of course it is best practice to shard, index and partition your database, but that is only when your data scales to a certain size. If you project that your database will not grow to 100s of GBs, then sharding and partitioning is simply unnecessary and adds additional overhead.
4.9 Good automation saves development time
Having a mature, reliable and resilient CI/CD pipeline is crucial for development. I have had to manually debug deployment pipelines a few time and it wastes a lot of time and introduces risks to projects. Therefore, by having a good CI/CD pipeline, you can get the most out of developers instead of having them do manual tasks.
Let's Connect 🍵
You made it to the end of my blog! I hope you enjoyed reading it and got something out of it. If you are interested in connecting with me, feel free to reach out to me on LinkedIn . I'm always up for a chat/or to work on exciting projects together!
Recent Blogs View All
genAI
LLM
backend
python
Yaplabs.ai
A genAI solution to language tutoring. Enabling language learners to be able to practice their language with an AI enabled real-time tutor.
2025-03-22 | 10 min read
Read→

Book
Microservices
Building Microservices
Recap of notes I have taken on this book of Building Microservices
2025-02-16 | 10 min read
Read→