
Fundamentals of Data Engineering

Kenneth Wong
2025-01-06
10 min read
A recap of of notes I have taken on this book. This is subjected to change as I am still reading the book
Book
Data Engineering
I did not take many notes from Chapter 1 - 7 as I was casually reading the book and I was already fairly familiar with the content already. So this recap will start from Chapter 8.
Chapter 8: Queries, Modelling and Transformations
Ways to optimize Queries
Pre-join tables: Materialize/cache joins that are frequently used to reduce the number of joins per query. A common use are CTEs (Common Table Expressions), they are temporary tables instead of nested subqueries.
Avoid full table scans: Prune queries by having conditions and only selecting columns that are required. This reduces the amount of data that needs to be scanned.
Enrichment - Combining a data store with a stream to enrich messages that are received. E.g If a message consists of product_id and user_id, and we want to add product and user address information. We would connect the relevant datastores to the stream to retrieve these informations.
Distributed Joins
Broadcast Joins
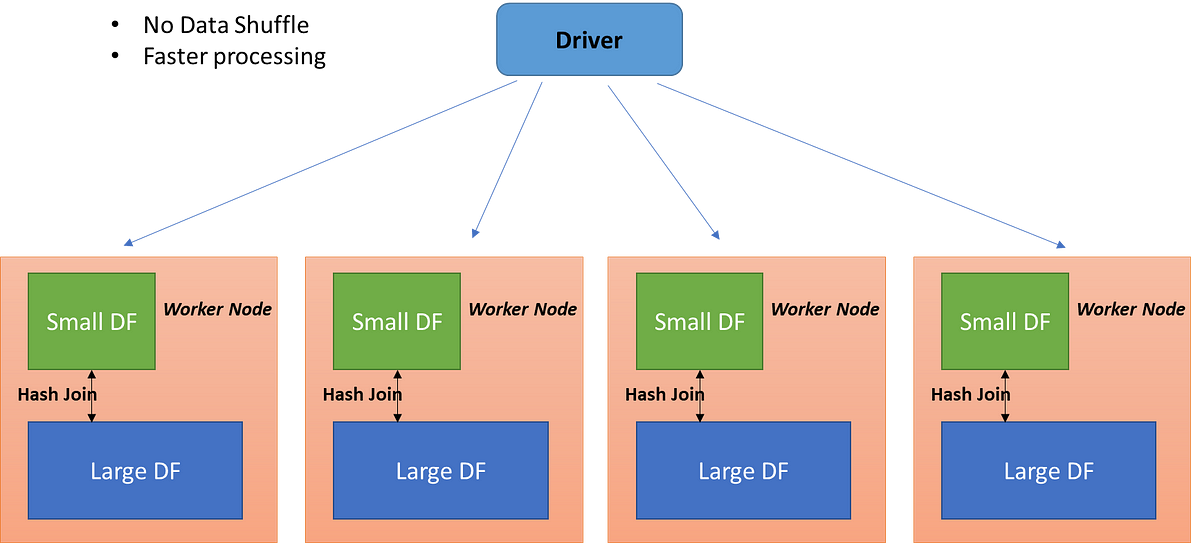
When there is a big size difference between 2 tables where size_of(table A) << size_of(table B), we can store table A in each individual node of the cluster and have table B be shared amongst all nodes. Then, each node can pull the relevant parts of table B to perform the join.
This only works if table A is small enough to fit in memory of the node, if not, we would have to look for an alternative like shuffle hash join. Instead of sending 2 tables across the network, each node only broadcasts the smaller table to be joined, saving data egress costs (in cloud).
Shuffle Hash Join
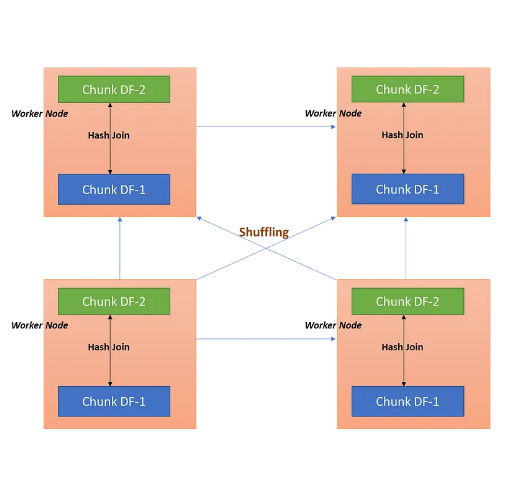
So this method is used when neither tables are small enough to be stored in memory. This join method is more computationally expensive compared to broadcast join due to the shuffling.
Each node has a separate partitions of both tables.
Then a hash function is applied to the join key and data is shuffled to the correct node to ensure the right rows are placed in the right node for processing.
Skewed join keys could occur (when a key occurs a lot more often than another key). This would lead to some nodes having significantly more data than other nodes.
ETL to ELT
Traditionally, data is extracted, transformed and loaded (ETL) into a data warehouse. However, with the increase in processing performance and capacity of data warehouses, most companies opt to dump data into the data warehouse and then transforming it there (ELT).
The cons of performing ELT instead of ETL is that a lot of companies simply dump their data without using it ever again (WORN - Write Once Read Never). The pros of ETL is that it forces businesses to transform their data to something useful before dumping it.
Federated Query
Federated query is a query across several datastores. Data warehouses can issue federated queries
Chapter 9: Transformation
There are mainly 3 types of analytics:
Business Analytics - Using historical and current data find historical trends and to forecast future trends to discover actionable insights.
Operational Analytics - Looking for realtime signals. Could be to detect realtime fraud, service monitoring, health-monitoring to perform immediate actions (auto-scale, notify).
Embedded Analytics - Analytics that are presented to clients to provide insight into their usage of the product (e.g a dashboard to monitor their sleep quality)
The main difference between business analytics and operational analytics is that business analytics focuses on planning and seeking out actionable insights from data whereas operation analytics look for immediate actions to take.
Embedded analytics has the challenge of having a higher QPS and demand compared to the other 2 analytics as all clients can query for these analytics. Therefore the availability and performance of embedded analytics is important.
Chapter 10: Security
FTP is generally unsafe and should be avoided in public networks as it is prone to MITM attacks, where attackers can snoop through file transfers.
Whitelisting IP addresses are important for restricting access to your service.
Cloud is considered more safe compared to on-premise hardware due to the zero-trust implementation and that everything on the cloud requires authentication and permission settings. However, on-premise systems like nuclear missles that are completely off-the internet is safer but is still prone to human errors.
Appendix
Find the right database for OLAP and OLTP
Depending on the use-case, the database that you choose is important. For instance, you would not use a full-text search database like Elastic Search as a primary database for write traffic (OLTP usecase). This is because with everywrite, elastic search have to re-index, making it slow and computational expensive. A better use case would be a traditional relational, KV store.
You also shouldn't use Column data stores for OLTP as each column is stored in a separate file, so R/W traffic would require accessing each file of each column, incurring high disk I/O. Moreover, depending on the distributed architecture, some systems actually distribute the file read task to each CPU core, making request parallelization infeasible as all CPU cores are busy with 1 request.
Database Engine
Database engines govern how data is stored on disk, including physical arrangement (block size, page table, page size...), data store serialization and indexes. This means that access patterns can be affected by the database engine as some physical arrangements might be better suite for sequential reads and others for random reads.
For random R/W, a SSD, memory buffer pool/cache would be better suited due to lower latency.
For sequential R/W, a HDD excels as it read/writes along the disk head over contiguous data blocks. Append-only log storage like LSM trees are also ideal for sequential access patterns.
Compression
Compression essentially how we serialize redundant information within an object and reduce the size of it. From what I can gather, it could be encoding words, the more redundant patterns are, the better performing the compression is.
Lossless Compression - Lossless compression means compressions where the original can be retrieved from the compressed version. Typically, this would mean that the compression ratio is less than ones of lossy compression as a schema would probably needed to be encoded as well.
When it comes to picking compression algorithms, there is a trade off between the compression ratio and CPU optimization during serialization/deserialization. To achieve better compression ratios, more resource intensive algorithms tend to be needed. However, nowadays where network bandwidths are significantly larger and data storage is cheaper compared to CPUs, it makes more sense to shift our focus on CPU optimization than compression ratio.
Conclusion
This book was a great read for software engineers to understand the role of data and how involved it actually is in the livlihood of a company, being an undercurrent in all stages of the company.
I have learnt a lot about current trends in data engineering, tools used and reasoning behind these tools. Short coming of certain trends that brought forth new trends. An example would be the move from batch processing to real-time processing, where the author predicts that most data stacks in the future will become a "live datastack", where data processing will be personalized to each individual user
I also particularly enjoyed the emphasis the author had on the end-user and their experience with the data. For instance, the author mentioned Operations and Marketing team trying to use the data, and data engineers should provide an intuitive interface for them in order to make their work more efficient as suppose to you having to send them an email of an excel file every week. Not only do data products support businesses, it also support other organizations within the company.
Let's Connect 🍵
You made it to the end of my blog! I hope you enjoyed reading it and got something out of it. If you are interested in connecting with me, feel free to reach out to me on LinkedIn . I'm always up for a chat/or to work on exciting projects together!
Recent Blogs View All
genAI
LLM
backend
python
Yaplabs.ai
A genAI solution to language tutoring. Enabling language learners to be able to practice their language with an AI enabled real-time tutor.
2025-03-22 | 10 min read
Read→

Book
Microservices
Building Microservices
Recap of notes I have taken on this book of Building Microservices
2025-02-16 | 10 min read
Read→