Google File System Paper Notes

Kenneth Wong
2025-01-09
10 min read
These are some notes that I took while reading the Google File System paper
engineering
System Design
Scoping the issue
One thing that stood out to me was how the author of the paper sketched out the scenario. They listed the access patterns of current system, the average file size and the lifecycle of a file in their file system. So they scoped that the current system:
Usually append only, no random writes (access from end of block)
Sequential reads (Reading file from top to bottom)
Small files - Occasionally large files of GBs exist, but most files are in the KBs, and there are billions of these files.
Infrequent access - Once written, files are rarely modified. They are mostly read and deleted.
Concurrent writes - Multiple clients can write to the same file concurrently as this is a distributed file system.
I think that this is a really important step before designing a system. It is critical to understand the existing behaviour of the system and plan around it to cover and optimize the core use cases of the system .
Architecture

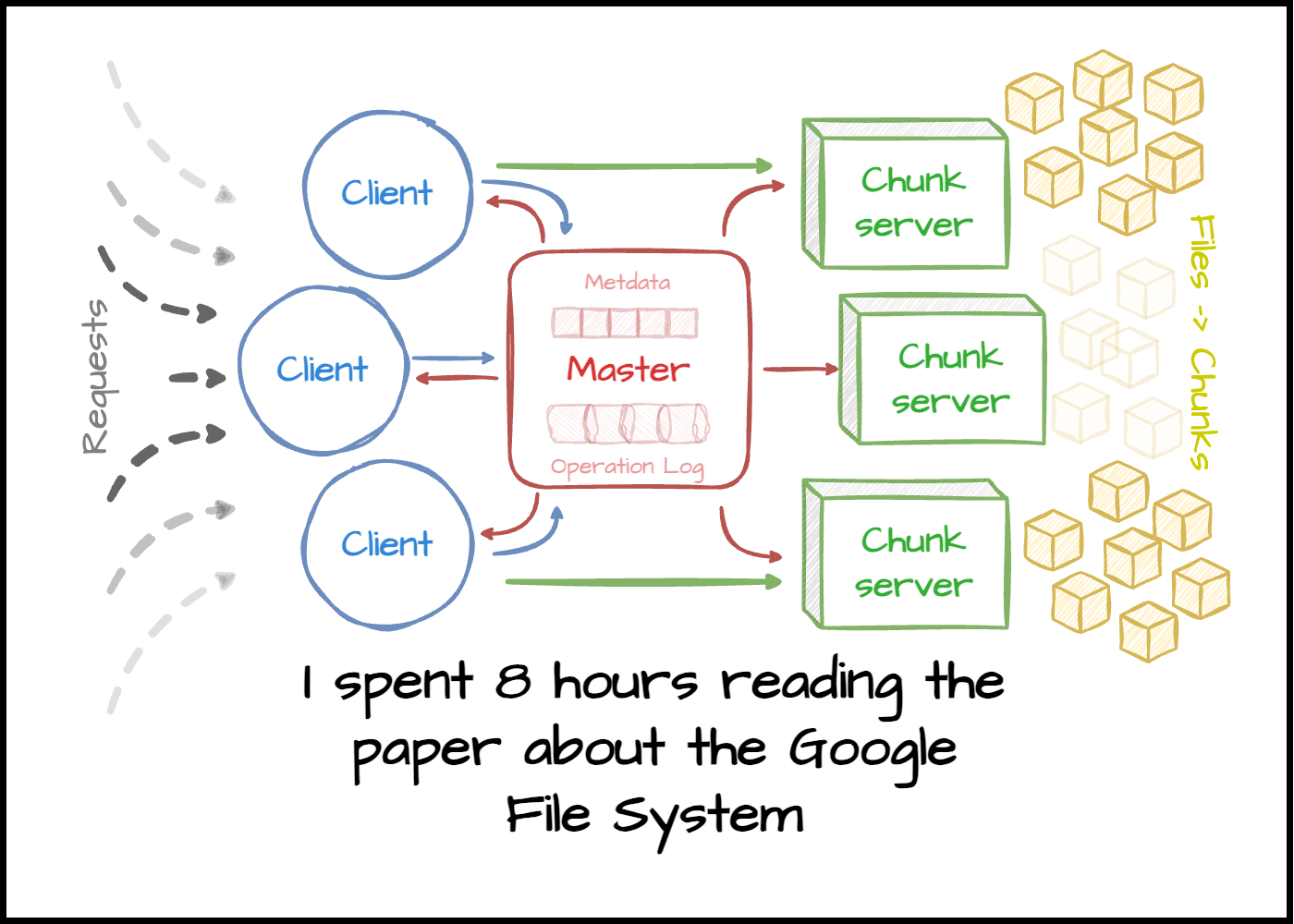
Master
Single Master - The master is a single point of failure, but it is not a bottleneck as it does not serve data. It is only responsible for metadata operations like directing the client to the write chunkserver to get the requested chunk. The reasoning behind the single master architecture was simplicity.
The master keeps the table in memory for fast lookup times. Despite a large file system, it manages to keep track of all the chunks due to prefix compression. This in-memory table of mappings are not persisted, this is because it can be re-created with the checkpoint logs and heartbeats from chunkservers.
In the case of failure, during reboot the master receives heartbeats from each chunkserver with information of what chunks each had and rebuild the table on the fly. According to the paper, the process of rebuilding the in-memory map takes only a couple of seconds.
Moreover, master also keeps a checkpoint log of critical metadata operations. The log is of limited size, such that when the log is of certain size, the master will create a checkpoint of the metadata and truncate the log. The log can be used to restore the state of the master. The log is also used by the shadow master (backup master) to keep in sync with the master as shadow master is read-only, meaning that it will have a fractional second of delay.
Chunkserver
The chunkserver is responsible for storing the actual data. The chunkserver is designed to be simple and reliable. It is designed to be simple as it only needs to store data and serve data. It is designed to be reliable as it is the only point of failure for data.
The chunkserver sends regular heartbeats to master to inform the master that it is still alive as well as the chunks it has and the version of it. If the chunk version of the chunkserver is outdated, then the master will instruct the chunkserver to update the chunk by pulling from the nearest chunkserver with the latest chunk.
By default GFS does lazy delete of files, meaning that files are not actually deleted, the name of the file is changed to hidden and it has 3 days before it gets wiped. Within those 3 days, users can restore the file by changing it's name back to the original name, this mechanism is to reverse accidental deletes.
Another feature is that chunkservers send master a list of chunks that are not being used, and the master can then decide to delete the chunk if it is not being used by any file, acting as a Garbage Collection.
Chunksize
So the chunksize is set the be 64MB, which is a lot larger than traditional design. This was implemented to prevent multiple client calls to the master as most calls will mostly lie within the same chunk due to the large chunk size.
Chunks are replicated to multiple chunkservers, and the master keeps track of which chunkserver keeps which chunks. In the case of a hot chunk (lots of read requests), master can increase the replication factor of the chunk to distribute the load.
Guarantees
Atomic operations
Master uses leases to ensure atomic operations on each chunk. A lease is associated with each chunk and clients would have to request the lease from master before writing. And since all read/write requests goes through master, master is the source of truth when it comes to mapping of chunks and chunkservers as well as chunk version.
In the case that master receives a heartbeat from a chunkserver that is greater than it's version. The master will assume that the lease mechanism failed and it didn't record the write, updating it's version to the latest one.
In the case the master receives a heartbeat from a chunkserver that is less than it's version. The master will send a request to the chunkserver to pull from another chunkserver with the up-to-date chunk.
Correctness
Each chunk is split into 64KB blocks, and within each block, 64 byte is used as checksum. This designs benefits the append write pattern of the system as there is no need to recompute entire checksum, the system only needs to get the last checksum and add the current one to compute the new check sum.
However, for random writes, it is required to read the first and last checksum to prevent overwriting a block that is already corrupted.
Redundancy
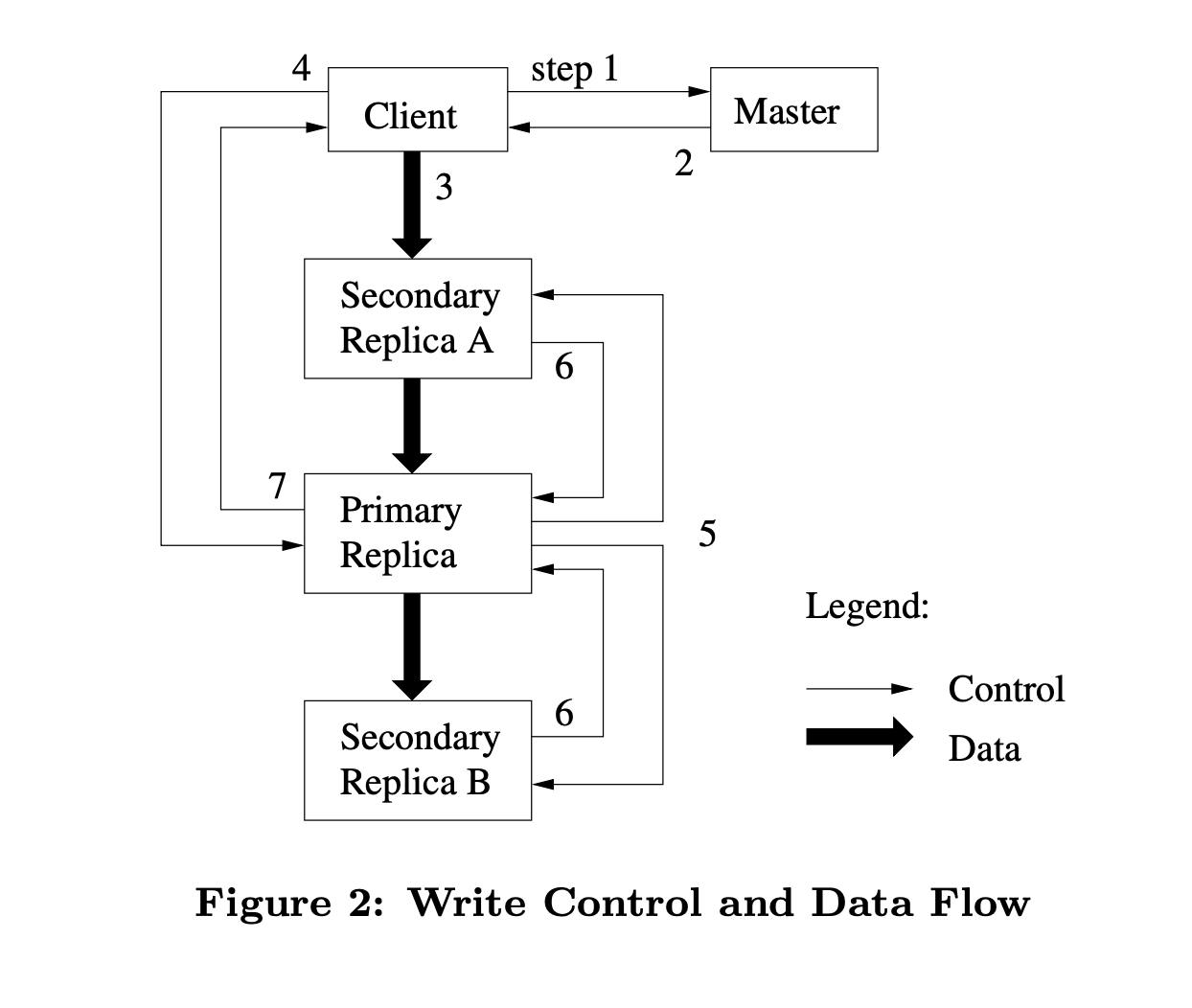
To bolster redundancy, the master has to determine which chunkserver to place each chunk and which chunkserver to hold the replicas. This is determined by several factors:
Capacity: The chunkserver whose capacity is less than average is more desirable
Less recent writes: The chunkserver that has less recent writes is more desirable
Different server racks: Ideally, the replicated chunks should be spread across different server racks in the case of server error. As we don't want irreversible dataloss if all the replicas were held in one server rack.
In terms of replication, replication is done through a tree manner through the TCP protocol. The master instructs the primary chunkserver to replicate the chunk to the other chunkservers. Each chunkserver connects to another chunkserver, and the chunkserver is determined by distance. Since it's using TCP protocol to transfer, the transfer to the next chunkserver can start the moment it receives the first packet of bytes. Therefore the overall latency of replication is T/B + R*L where T is payload size, B is network throughput bandwidth, R is # of replicas and L is network latency to transfer bytes between 2 chunkservers.
Conclusion
I scanned pass the results and metrics section of the paper as it was pretty dated considering the magnitude of files and latency in nowaday data systems.
Overall, this was a great read that strengthen my knowledge on system design. I learnt a lot about trade-offs, building a system to accomodate the existing use case as well as distributed programming with the leases.
Moreover, this paper highlighted how fundamental heartbeats are in distributed systems and how it is used to coordinate a complex system and self-heal whenever discrepancies arise (and they will).
I really appreciated the design choice of keep the table in memory and not persisting it to prevent any overhead. In terms of practicality, it made perfect sense to read from the chunkservers as they are the ones holding the chunks, so they will have the latest mapping for themselves.
Let's Connect 🍵
You made it to the end of my blog! I hope you enjoyed reading it and got something out of it. If you are interested in connecting with me, feel free to reach out to me on LinkedIn . I'm always up for a chat/or to work on exciting projects together!
Recent Blogs View All
genAI
LLM
backend
python
Yaplabs.ai
A genAI solution to language tutoring. Enabling language learners to be able to practice their language with an AI enabled real-time tutor.
2025-03-22 | 10 min read
Read→

Book
Microservices
Building Microservices
Recap of notes I have taken on this book of Building Microservices
2025-02-16 | 10 min read
Read→