
Uvicorn, Gunicorn and FastAPI

Kenneth Wong
2025-02-13
10 min read
Investigative work I did for a fastAPI project that I am currently working on
backend
python
Recently I have been working on a project that uses fastAPI as the webserver. Our project is low on CPU utilization. Our webserver mainly sends out HTTP requests to 3rd party APIs and servers the response to the client. Hence, our workload is IO-bound.
Python has the GIL (Global Interpreter Lock) that prevents threads from running in parallel, meaning that multithreading will still be ran only by the main thread. This made me look deeper into how we can optimize and scale our fastapi application to serve more requests.
Fastapi

Fastapi incorporates Asyncio to handle concurrent requests, meaning that the main thread can pre-empt async functions to handle incoming requests. This is great for IO-bound applications as the bottleneck is IO and not the CPU.
With that said, it is also important not to include blocking functions in the async functions as it will essentially negate the purpose of using asyncio, it will block the main thread and not allow other requests to be handled. A famous pitfall is using time.sleep().
Multithreading

I use multithreading when I need to make concurrent network calls to reduce latency. This has a smaller memory footprint and allows easy memory sharing between threads. It makes more sense to spin threads than to spin processes in this case as network calls are IO-bound.
Multiprocessing
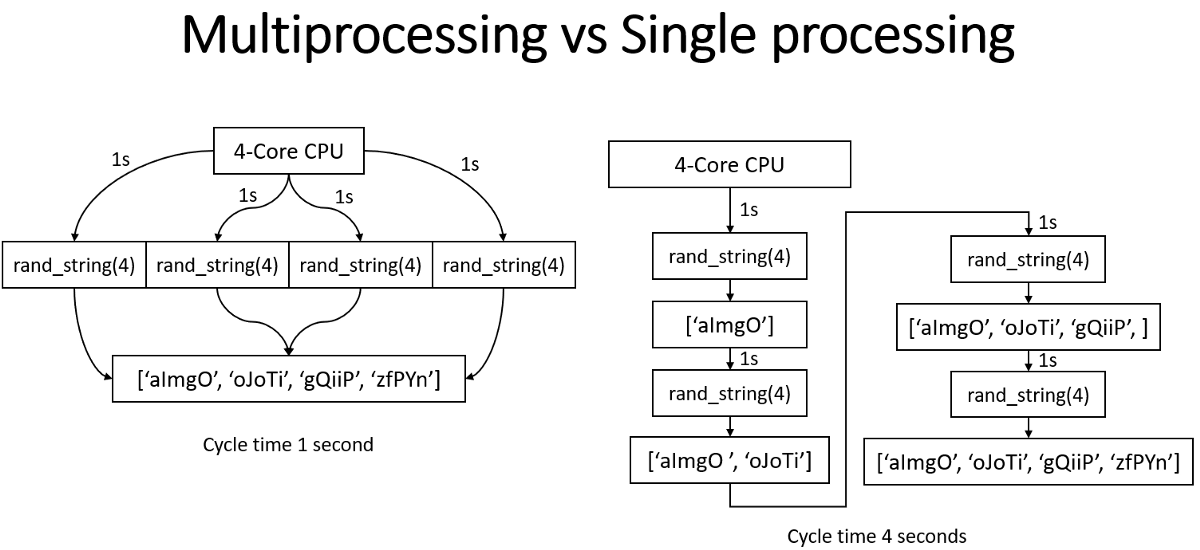
I use multiprocessing when I need to handle CPU-bound tasks. For example, I needed to compress mp3 files in the background, so to prevent blocking the main thread, I spun up a new process to handle the compression, allowing the main thread to continue serving requests.
Multiprocessing has a larger memory footprint as we copy the entire memory space for each process. This also means that memory sharing is more difficult. Fortunately, each mp3 file was unique so we did not run into any synchronization issues or requirement of mutex.
Uvicorn and Gunicorn

Uvicorn and Gunicorn are process managers that bind to a port. Each worker is responsible for intercepting a users request, getting the scope and data and passing the data to the application running on the worker. They help with scaling the application internally (within the same container) by spinning up workers to loadbalance the requests. For external scaling, we would probably need a Load Balancer and a container orchestration tool like Kubernetes.
WSGI and ASGI
WSGI (Web Server Gateway Interface) is a specification for a Python interface to web servers. It is a synchronous interface, meaning that each request is handled by one worker.
ASGI (Asynchronous Server Gateway Interface) is a specification for a Python interface to web servers. It is an asynchronous interface, meaning that each request is handled by one worker. It is the successor to WSGI as it can handle asynchronous operations, which is a big part of modern web development due to the increase in outbound network requests.
Gunicorn is a WSGI server, hence it is not compatible with FastAPI as FastAPI is an ASGI application as mentioned above. Gunicorn provides you finer grain control over the workers and the application. Moreover, Gunicorn does not support persistent connections, it terminates once a response is sent, regardless whether there is a keep alive header.
However, Uvicorn has a Gunicorn compatible worker that allows us to run Gunicorn with FastAPI. This is great as we can have finer grain control over the workers and internally scale up the # of requests we can handle.
According to Gunicorn, it is recommended to spin up 2*cpu_cores + 1 workers, as it is under the assumption that for each core, there will be a worker responsible for processing requests and another for receiving requests. There is no golden number for the number of workers, too little and you will not be able to utilize the full potential of the CPU, too many and you will have idle workers taking up memory. In the end, trial and error is the best way to determine the number of workers that your application needs.
A typical Gunicorn command to run FastAPI would be:
gunicorn main:app --workers 4 --worker-class uvicorn.workers.UvicornWorker
Conclusion
It was very insightful to learn about how web-servers like Flask, Django and FastAPI work internally. I used to just run the application without thinking. But after learning about scaling and asyncio, it was important for me to learn the lifecycle of a request and what was the entire process of the request was from client to server.
Let's Connect 🍵
You made it to the end of my blog! I hope you enjoyed reading it and got something out of it. If you are interested in connecting with me, feel free to reach out to me on LinkedIn . I'm always up for a chat/or to work on exciting projects together!
Recent Blogs View All
genAI
LLM
backend
python
Yaplabs.ai
A genAI solution to language tutoring. Enabling language learners to be able to practice their language with an AI enabled real-time tutor.
2025-03-22 | 10 min read
Read→

Book
Microservices
Building Microservices
Recap of notes I have taken on this book of Building Microservices
2025-02-16 | 10 min read
Read→